BaseMultiTableInnerInterceptor源码解读
本文最后更新于 2026年1月12日
一、概述
BaseMultiTableInnerInterceptor是MyBatis-Plus中的一个抽象类,位于mybatis-plus-jsqlparser-4.9模块中com.baomidou.mybatisplus.extension.plugins.inner包下,提供解析和重写SQL功能,MyBatis-Plus的数据权限(TenantLineInnerInterceptor)插件和多租户(DataPermissionInterceptor)插件均继承了BaseMultiTableInnerInterceptor类来实现对应的功能。
本文基于MyBatis-Plus的3.5.9版本的源码,并fork了代码: https://github.com/changelzj/mybatis-plus/tree/lzj-3.5.9
public abstract class BaseMultiTableInnerInterceptor
extends JsqlParserSupport
implements InnerInterceptor {
protected void processSelectBody(Select selectBody, final String whereSegment) {...}
protected Expression andExpression(Table table, Expression where, final String whereSegment) {...}
protected void processPlainSelect(final PlainSelect plainSelect, final String whereSegment) {...}
private List<Table> processFromItem(FromItem fromItem, final String whereSegment) {...}
protected void processWhereSubSelect(Expression where, final String whereSegment) {...}
protected void processSelectItem(SelectItem selectItem, final String whereSegment) {...}
protected void processFunction(Function function, final String whereSegment) {...}
protected void processOtherFromItem(FromItem fromItem, final String whereSegment) {...}
private List<Table> processSubJoin(ParenthesedFromItem subJoin, final String whereSegment) {...}
private List<Table> processJoins(List<Table> mainTables, List<Join> joins, final String whereSegment) {...}
protected Expression builderExpression(Expression currentExpression, List<Table> tables, final String whereSegment) {...}
public abstract Expression buildTableExpression(final Table table, final Expression where, final String whereSegment);
}二、执行流程
BaseMultiTableInnerInterceptor实现了InnerInterceptor接口中的beforeQuery(),beforePrepare()方法,实际上是子类去间接实现的,MyBatis-Plus就是对实现这个接口的类进行回调,在查询SQL即将执行时调用beforeQuery(),在增删改SQL即将执行前调用beforePrepare(),beforeQuery()中再去调用parserSingle(),beforePrepare()再去调用parserMulti()
查询语句只能一次执行一条,增删改语句可以用分号间隔一次执行多条。故
beforeQuery()调用parserSingle(),beforePrepare()调用parserMulti()
@Override
public void beforeQuery(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
if (InterceptorIgnoreHelper.willIgnoreDataPermission(ms.getId())) {
return;
}
PluginUtils.MPBoundSql mpBs = PluginUtils.mpBoundSql(boundSql);
mpBs.sql(parserSingle(mpBs.sql(), ms.getId()));
}
@Override
public void beforePrepare(StatementHandler sh, Connection connection, Integer transactionTimeout) {
PluginUtils.MPStatementHandler mpSh = PluginUtils.mpStatementHandler(sh);
MappedStatement ms = mpSh.mappedStatement();
SqlCommandType sct = ms.getSqlCommandType();
if (sct == SqlCommandType.UPDATE || sct == SqlCommandType.DELETE) {
if (InterceptorIgnoreHelper.willIgnoreDataPermission(ms.getId())) {
return;
}
PluginUtils.MPBoundSql mpBs = mpSh.mPBoundSql();
mpBs.sql(parserMulti(mpBs.sql(), ms.getId()));
}
}
parserSingle(),parserMulti()是BaseMultiTableInnerInterceptor从JsqlParserSupport抽象类继承而来的,JsqlParserSupport是MyBatis-Plus基于JsqlParser(JSQLParser详见:SQL解析工具JSQLParser)封装的一个工具类,这个类的功能非常简单,作用是判断SQL是增删改查的哪一种类型,然后分别调用对应的方法开始解析。
public abstract class JsqlParserSupport {
/**
* 日志
*/
protected final Log logger = LogFactory.getLog(this.getClass());
public String parserSingle(String sql, Object obj) {
if (logger.isDebugEnabled()) {
logger.debug("original SQL: " + sql);
}
try {
Statement statement = JsqlParserGlobal.parse(sql);
return processParser(statement, 0, sql, obj);
} catch (JSQLParserException e) {
throw ExceptionUtils.mpe("Failed to process, Error SQL: %s", e.getCause(), sql);
}
}
public String parserMulti(String sql, Object obj) {
if (logger.isDebugEnabled()) {
logger.debug("original SQL: " + sql);
}
try {
// fixed github pull/295
StringBuilder sb = new StringBuilder();
Statements statements = JsqlParserGlobal.parseStatements(sql);
int i = 0;
for (Statement statement : statements) {
if (i > 0) {
sb.append(StringPool.SEMICOLON);
}
sb.append(processParser(statement, i, sql, obj));
i++;
}
return sb.toString();
} catch (JSQLParserException e) {
throw ExceptionUtils.mpe("Failed to process, Error SQL: %s", e.getCause(), sql);
}
}
/**
* 执行 SQL 解析
*
* @param statement JsqlParser Statement
* @return sql
*/
protected String processParser(Statement statement, int index, String sql, Object obj) {
if (logger.isDebugEnabled()) {
logger.debug("SQL to parse, SQL: " + sql);
}
if (statement instanceof Insert) {
this.processInsert((Insert) statement, index, sql, obj);
} else if (statement instanceof Select) {
this.processSelect((Select) statement, index, sql, obj);
} else if (statement instanceof Update) {
this.processUpdate((Update) statement, index, sql, obj);
} else if (statement instanceof Delete) {
this.processDelete((Delete) statement, index, sql, obj);
}
sql = statement.toString();
if (logger.isDebugEnabled()) {
logger.debug("parse the finished SQL: " + sql);
}
return sql;
}
/**
* 新增
*/
protected void processInsert(Insert insert, int index, String sql, Object obj) {
throw new UnsupportedOperationException();
}
/**
* 删除
*/
protected void processDelete(Delete delete, int index, String sql, Object obj) {
throw new UnsupportedOperationException();
}
/**
* 更新
*/
protected void processUpdate(Update update, int index, String sql, Object obj) {
throw new UnsupportedOperationException();
}
/**
* 查询
*/
protected void processSelect(Select select, int index, String sql, Object obj) {
throw new UnsupportedOperationException();
}
}
当调用parserSingle()或parserMulti()并传入SQL时,会在processParser()方法中先判断是哪一种Statement,然后分别强转为具体的Select、Update、Delete、Insert对象,再调用子类(例如:DataPermissionInterceptor)间接继承并重写的processSelect()、processDelete()、processUpdate()方法。
子类中的processSelect()方法会再调用父类BaseMultiTableInnerInterceptor中的processSelectBody()对查询进行解析,processUpdate()和processDelete()同理。这样设计的原因可能是由具体的子类根据功能来最终确定解析和重写逻辑,而BaseMultiTableInnerInterceptor只提供解析和重写能力不负责不同场景下的具体逻辑实现。
@Override
protected void processSelect(Select select, int index, String sql, Object obj) {
if (dataPermissionHandler == null) {
return;
}
if (dataPermissionHandler instanceof MultiDataPermissionHandler) {
// 参照 com.baomidou.mybatisplus.extension.plugins.inner.TenantLineInnerInterceptor.processSelect 做的修改
final String whereSegment = (String) obj;
processSelectBody(select, whereSegment);
List<WithItem> withItemsList = select.getWithItemsList();
if (!CollectionUtils.isEmpty(withItemsList)) {
withItemsList.forEach(withItem -> processSelectBody(withItem, whereSegment));
}
} else {
// 兼容原来的旧版 DataPermissionHandler 场景
if (select instanceof PlainSelect) {
this.setWhere((PlainSelect) select, (String) obj);
} else if (select instanceof SetOperationList) {
SetOperationList setOperationList = (SetOperationList) select;
List<Select> selectBodyList = setOperationList.getSelects();
selectBodyList.forEach(s -> this.setWhere((PlainSelect) s, (String) obj));
}
}
}
/**
* update 语句处理
*/
@Override
protected void processUpdate(Update update, int index, String sql, Object obj) {
final Expression sqlSegment = getUpdateOrDeleteExpression(update.getTable(), update.getWhere(), (String) obj);
if (null != sqlSegment) {
update.setWhere(sqlSegment);
}
}
/**
* delete 语句处理
*/
@Override
protected void processDelete(Delete delete, int index, String sql, Object obj) {
final Expression sqlSegment = getUpdateOrDeleteExpression(delete.getTable(), delete.getWhere(), (String) obj);
if (null != sqlSegment) {
delete.setWhere(sqlSegment);
}
}
protected Expression getUpdateOrDeleteExpression(final Table table, final Expression where, final String whereSegment) {
if (dataPermissionHandler == null) {
return null;
}
if (dataPermissionHandler instanceof MultiDataPermissionHandler) {
return andExpression(table, where, whereSegment);
} else {
// 兼容旧版的数据权限处理
return dataPermissionHandler.getSqlSegment(where, whereSegment);
}
}三、源码解读
与更新和删除语句的解析相比,对查询语句进行解析和重写的逻辑是更加复杂的,步骤也更多,需要解析到SQL语句的各个部分,分为多个方法,方法间互相配合实现对复杂查询SQL语句的解析和重写
执行的大致流程如下:
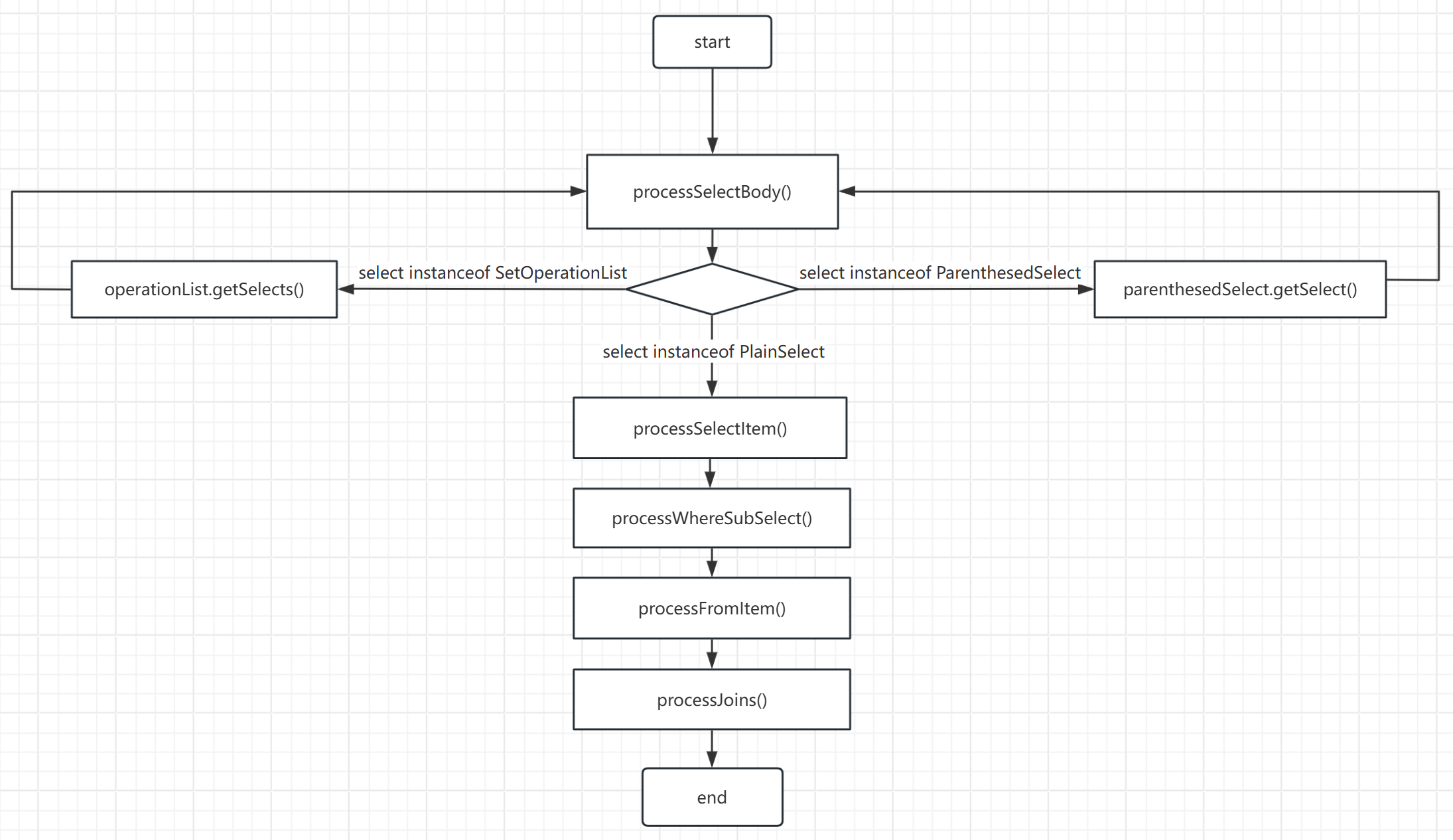
如SQL结构复杂,需要先将一个复杂SQL拆分为若干简单SQL,然后依次对每个SQL需要重写条件的地方(select xx,from xx,join xx,where xx)进行表和条件解析然后追加过滤条件,如果遇到子查询需要递归解析子查询直到SQL所有部分都被解析到
3.1 processSelectBody
该方法是解析SELECT语句的入口方法,会先对复杂的SELECT语句进行简化拆分,再分别调用processPlainSelect()来解析每个部分
protected void processSelectBody(Select selectBody, final String whereSegment) {
if (selectBody == null) {
return;
}
if (selectBody instanceof PlainSelect) {
processPlainSelect((PlainSelect) selectBody, whereSegment);
} else if (selectBody instanceof ParenthesedSelect) {
ParenthesedSelect parenthesedSelect = (ParenthesedSelect) selectBody;
processSelectBody(parenthesedSelect.getSelect(), whereSegment);
} else if (selectBody instanceof SetOperationList) {
SetOperationList operationList = (SetOperationList) selectBody;
List<Select> selectBodyList = operationList.getSelects();
if (CollectionUtils.isNotEmpty(selectBodyList)) {
selectBodyList.forEach(body -> processSelectBody(body, whereSegment));
}
}
}解读:
该方法传入一个jsqlparser的Select对象,因为有的SELECT语句结构比较复杂,需要化繁为简进行拆分然后对每个部分分别进行解析,这里MyBatis-Plus考虑了三种情况:
PlainSelect:最标准的SELECT语句格式,直接调用
processPlainSelect(PlainSelect plainSelect)方法开始解析即可ParenthesedSelect:带括号的子查询,先去掉括号,将括号内SELECT语句再次调用
processSelectBody(Select select)进行递归解析,直到格式满足PlainSelectSetOperationList:多个SELECT语句通过
UNION、UNION ALL等组合为一个整体的SELECT语句的情况,分别拆开取出每一段SELECT,将每一段SELECT再次调用processSelectBody(Select select)进行递归解析,直到格式满足PlainSelect
还有一种select语句中带有
with的情况,要把with中的查询语句提取进行解析,不过不是在这里处理的,而是在子类的processSelect方法中,调用processSelectBody方法之后
3.2 processPlainSelect
该方法用于开启一个对常规形式的SELECT语句的解析
protected void processPlainSelect(final PlainSelect plainSelect, final String whereSegment) {
//#3087 github
List<SelectItem<?>> selectItems = plainSelect.getSelectItems();
if (CollectionUtils.isNotEmpty(selectItems)) {
selectItems.forEach(selectItem -> processSelectItem(selectItem, whereSegment));
}
// 处理 where 中的子查询
Expression where = plainSelect.getWhere();
processWhereSubSelect(where, whereSegment);
// 处理 fromItem
FromItem fromItem = plainSelect.getFromItem();
List<Table> list = processFromItem(fromItem, whereSegment);
List<Table> mainTables = new ArrayList<>(list);
// 处理 join
List<Join> joins = plainSelect.getJoins();
if (CollectionUtils.isNotEmpty(joins)) {
processJoins(mainTables, joins, whereSegment);
}
// 当有 mainTable 时,进行 where 条件追加
if (CollectionUtils.isNotEmpty(mainTables)) {
plainSelect.setWhere(builderExpression(where, mainTables, whereSegment));
}
}解读:
该方法分别对SELECT语句中需要追加条件的部位进行解析,包括SELECT部分的[SelectItem] ,FROM部分的[FromItem],WHERE后面的条件(中的子查询)[Expression],JOIN连接查询的部分[JOIN]
SELECT
[SelectItem]
FROM
[FromItem]
LEFT/RIGHT/INNER JOIN [JOIN]
WHERE
[Expression]解析完成后会调用plainSelect.setWhere(builderExpression(where, mainTables))对需要最终查出所有数据的驱动表进行WHERE条件重写,详见:3.10 buildTableExpression,到底哪个表是驱动表,会由processJoins方法进行计算确认,具体见:3.7 processJoins
3.3 processSelectItem
该方法用于解析和重写SELECT列表中带有SELECT的语法结构
protected void processSelectItem(SelectItem selectItem, final String whereSegment) {
Expression expression = selectItem.getExpression();
if (expression instanceof Select) {
processSelectBody(((Select) expression), whereSegment);
} else if (expression instanceof Function) {
processFunction((Function) expression, whereSegment);
} else if (expression instanceof ExistsExpression) {
ExistsExpression existsExpression = (ExistsExpression) expression;
processSelectBody((Select) existsExpression.getRightExpression(), whereSegment);
}
}
解读:
该方法会对SELECT列表项中的子查询语句,函数参数中的SELECT语句和EXIST结构中的SELECT语句进行解析
SQL举例说明:
SELECT
id,
employee_id,
fun_first_name( (select n from users u where u.id = e.uid) ) as first_name ,
(select last_name from users u where u.id = e.uid) as last_name,
EXISTS(SELECT 1 FROM projects WHERE manager_id = e.employee_id) AS is_manager
FROM
employees e;解析并处理后得到SQL:
SELECT
id,
employee_id,
fun_first_name((SELECT n FROM users u WHERE u.id = e.uid AND users.scope = 12)) AS first_name,
(SELECT last_name FROM users u WHERE u.id = e.uid AND users.scope = 12) AS last_name,
EXISTS (SELECT 1 FROM projects WHERE manager_id = e.employee_id AND projects.scope = 12) AS is_manager
FROM
employees e
WHERE
employees.scope = 12
EXISTS (...) as ..不能写成( EXISTS (...) ) as ..,否则不会被解析为Select而是会被解析为Parenthesis,而该方法没有提供Parenthesis的解析,会导致被忽略
3.4 processWhereSubSelect
该方法用于对WHERE后面的SQL语句结构进行解析和追加过滤条件,主要是在分段拆分解析where表达式,代码实现的方式非常精巧,分析起来自然稍微有一点难度,但是远比processJoins()简单的多。
protected void processWhereSubSelect(Expression where, final String whereSegment) {
if (where == null) {
return;
}
if (where instanceof FromItem) {
processOtherFromItem((FromItem) where, whereSegment);
return;
}
if (where.toString().indexOf("SELECT") > 0) {
/* 通过if (where.toString().indexOf("SELECT") > 0)判断当前的where语句中是否含有select关键字
如果有的话说明where条件后的表达式存在子查询,又会马上进入以下逻辑对子查询的表进行解析和追加条件*/
if (where instanceof BinaryExpression) {
// 比较符号 , and , or , 等等
BinaryExpression expression = (BinaryExpression) where;
processWhereSubSelect(expression.getLeftExpression(), whereSegment);
processWhereSubSelect(expression.getRightExpression(), whereSegment);
}
else if (where instanceof InExpression) {
// in
InExpression expression = (InExpression) where;
Expression inExpression = expression.getRightExpression();
// in的是子查询才处理
if (inExpression instanceof Select) {
processSelectBody(((Select) inExpression), whereSegment);
}
}
else if (where instanceof ExistsExpression) {
// exists
ExistsExpression expression = (ExistsExpression) where;
processWhereSubSelect(expression.getRightExpression(), whereSegment);
}
else if (where instanceof NotExpression) {
// not exists , not in ...
// 如果是not的结构,还需要expression.getExpression()后再递归调用processWhereSubSelect()特殊处理
NotExpression expression = (NotExpression) where;
processWhereSubSelect(expression.getExpression(), whereSegment);
}
else if (where instanceof Parenthesis) {
Parenthesis expression = (Parenthesis) where;
processWhereSubSelect(expression.getExpression(), whereSegment);
}
}
}解读:
传进来的参数Expression where是一个JSQLParser的Expression类型,因为WHERE条件中可能解析出很多不同类型的SQL语法结构,这些结构都在processWhereSubSelect方法中一并处理,因此这里用了一个偏底层可以泛指这些结构的Expression对象作为参数,主要需要处理的就是子查询和返回布尔值的各种表达式。
解析时首先判断传进来的Expression是否为FromItem结构(通常就是子查询),如是直接传入processOtherFromItem()处理子查询,否则进一步判断该结构的语句体中是否有where关键字,如有说明存在子查询需要进一步处理,接着就会判断该结构是否为为比较符号(and,or, =, >等)衔接的BinaryExpression结构。
如果是BinaryExpression结构则先拆分为左右两部分,拆成的左右两部分可能有一侧还是BinaryExpression结构,甚至两侧都还是BinaryExpression结构,这样的话就要递归调用processWhereSubSelect()方法将拆分后的结构再次拆分,这样整个表达式便越拆越小,直到某个拆出的结构满足where instanceof FromItem后,再把该结构传入processOtherFromItem()处理子查询。
如果拆出的结构既不是FromItem又不是BinaryExpression,则需要再判断它是否属于in, exists,如是且有子查询结构,则将子查询剔出调用processSelectBody()进行解析子查询。
如果是not的结构,还需要expression.getExpression()后再递归调用processWhereSubSelect()特殊处理,因为not的情况比较特殊,不能一口气把子查询剔干净,实测not exists(select ...)不能拆出(select ...),只能先拆分出exists(select ...),再调用processWhereSubSelect走到else if (where instanceof ExistsExpression)分支后再拆出(select ...),not in同理,因此NotExpression结构不能直接拿到子查询,剔出来的是not后面的结构,要再递归调用processWhereSubSelect(),而不是直接processSelectBody()。
案例说明:
SELECT name
FROM user u
WHERE u.math_score < (SELECT avg(score) FROM math )
OR u.english_score > (SELECT avg(score) FROM english )
AND (SELECT order_num FROM student ) = u.order_num
AND u.role_id IN (SELECT id FROM role )
AND EXISTS ( SELECT * FROM customer WHERE id = 6 )
AND NOT EXISTS ( SELECT * FROM customer WHERE id = 7 )在这段SQL中,通过plainSelect.getWhere()得到的where的部分是:u.math_score < (SELECT avg(score) FROM math) OR u.english_score > (SELECT avg(score) FROM english) AND (SELECT order_num FROM student) = u.order_num AND u.role_id IN (SELECT id FROM role) AND EXISTS (SELECT * FROM customer WHERE id = 6) AND NOT EXISTS (SELECT * FROM customer WHERE id = 7),该部分会作为参数传入Expression where中,这段复杂的where表达式中的子查询是采用拆分的方法解析到的,具体解析和追加的步骤如下:
第一次拆分:首先where结构被整个传入,where instanceof FromItem == false且where instanceof BinaryExpression == true,整个where表达式将被processWhereSubSelect(expression.getLeftExpression(), whereSegment)拆分为:
- expression.getLeftExpression() =>
u.math_score < (SELECT avg(score) FROM math) - expression.getRightExpression() =>
u.english_score > (SELECT avg(score) FROM english) AND (SELECT order_num FROM student) = u.order_num AND u.role_id IN (SELECT id FROM role) AND EXISTS (SELECT * FROM customer WHERE id = 6) AND NOT EXISTS (SELECT * FROM customer WHERE id = 7)
第二次拆分:执行到processWhereSubSelect(expression.getLeftExpression(), whereSegment)处,将u.math_score < (SELECT avg(score) FROM math)传入processWhereSubSelect递归解析,这次执行仍然满足where instanceof FromItem == false,where instanceof BinaryExpression == true,u.math_score < (SELECT avg(score) FROM math)将被拆分为:
- expression.getLeftExpression() =>
u.math_score - expression.getRightExpression() =>
(SELECT avg(score) FROM math)
接下来还会递归执行到processWhereSubSelect(expression.getLeftExpression(), whereSegment)处,将u.math_score传入processWhereSubSelect递归解析,没有满足条件的分支直接跳过,紧接着执行processWhereSubSelect(expression.getRightExpression(), whereSegment),将(SELECT avg(score) FROM math)传入processWhereSubSelect递归解析,这次执行满足where instanceof FromItem的条件,不需要拆分,执行processOtherFromItem对(SELECT avg(score) FROM math)进行过滤条件追加,至此,第一步拆分拆出来的bexpression.getLeftExpression()部分解析处理完成,第一段递归随即跳出。
第三次拆分:第一步拆分出来的expression.getRightExpression()开始传入processWhereSubSelect进行递归解析,这部分也满足where instanceof FromItem == false,where instanceof BinaryExpression == true,将被拆分为:
- expression.getLeftExpression() =>
u.english_score > (SELECT avg(score) FROM english) AND (SELECT order_num FROM student) = u.order_num AND u.role_id IN (SELECT id FROM role) AND EXISTS (SELECT * FROM customer WHERE id = 6) - expression.getRightExpression() =>
NOT EXISTS (SELECT * FROM customer WHERE id = 7)
同理,取出expression.getLeftExpression()进行第四次拆分:
where instanceof BinaryExpression:
- expression.getLeftExpression() =>
u.english_score > (SELECT avg(score) FROM english) AND (SELECT order_num FROM student) = u.order_num AND u.role_id IN (SELECT id FROM role) - expression.getRightExpression() =>
EXISTS (SELECT * FROM customer WHERE id = 6)
第五次拆分:
where instanceof BinaryExpression:
- expression.getLeftExpression() =>
u.english_score > (SELECT avg(score) FROM english) AND (SELECT order_num FROM student) = u.order_num - expression.getRightExpression() =>
u.role_id IN (SELECT id FROM role)
第六次拆分:
where instanceof BinaryExpression:
- expression.getLeftExpression() =>
u.english_score > (SELECT avg(score) FROM english) - expression.getRightExpression() =>
(SELECT order_num FROM student) = u.order_num
第七次拆分:
where instanceof BinaryExpression:
- expression.getLeftExpression() =>
u.english_score - expression.getRightExpression() =>
(SELECT avg(score) FROM english)
至此,第一步拆分出来的bexpression.getLeftExpression()已经拆分到不可拆分的程度,开始递归expression.getRightExpression()部分,并一路反算回去:
处理第七次拆分的RightExpression:
where instanceof BinaryExpression:
- expression.getLeftExpression() =>
u.english_score - expression.getRightExpression() =>
(SELECT avg(score) FROM english)
u.english_score不满足任何分支,直接跳过,(SELECT avg(score) FROM english)是子查询,调用processOtherFromItem()处理。
处理第六次拆分的RightExpression:
where instanceof BinaryExpression:
- expression.getLeftExpression() =>
(SELECT order_num FROM student) - expression.getRightExpression() =>
u.order_num
(SELECT order_num FROM student)是子查询,调用processOtherFromItem()处理,u.order_num不满足任何分支,直接跳过
处理第五次拆分的RightExpression:
where instanceof InExpression:
- expression.getLeftExpression() =>
u.role_id - expression.getRightExpression() =>
(SELECT id FROM role)
u.role_id不满足任何分支,直接跳过,(SELECT id FROM role),通过IN解析子查询,然后调用processOtherFromItem()处理
处理第四次拆分的RightExpression:
where instanceof ExistsExpression:
- expression.getRightExpression() =>
(SELECT * FROM customer WHERE id = 6)
EXISTS (SELECT * FROM customer WHERE id = 6)满足where instanceof ExistsExpression的情况,提取出(SELECT * FROM customer WHERE id = 6)子查询,调用processOtherFromItem()处理
处理第三次拆分的RightExpression:
where instanceof NotExpression:
- expression.getExpression() =>
EXISTS (SELECT * FROM customer WHERE id = 7)
先调用processWhereSubSelect()从NOT EXISTS (SELECT * FROM customer WHERE id = 7)中提取出EXISTS (SELECT * FROM customer WHERE id = 7),再走到where instanceof ExistsExpression分支提取出子查询(SELECT * FROM customer WHERE id = 7)调用processOtherFromItem()处理
至此,WHERE语句中所有需要追加条件的表都解析追加完成了,最终得到SQL如下:
SELECT name FROM user u
WHERE (u.math_score < (SELECT avg(score) FROM math WHERE math.scope = 12)
OR u.english_score > (SELECT avg(score) FROM english WHERE english.scope = 12)
AND (SELECT order_num FROM student WHERE student.scope = 12) = u.order_num
AND u.role_id IN (SELECT id FROM role WHERE role.scope = 12)
AND EXISTS (SELECT * FROM customer WHERE id = 6 AND customer.scope = 12)
AND NOT EXISTS (SELECT * FROM customer WHERE id = 7 AND customer.scope = 12))
AND user.scope = 12这个方法看似有点复杂,只要编写一个SQL,运行一下,并DEBUG跟着一路调试下来,就会发现一点也不难理解,还能体会到这种实现的精巧之处
3.5 processOtherFromItem
主要就是处理子查询ParenthesedSelect
/**
* 处理子查询等
*/
protected void processOtherFromItem(FromItem fromItem, final String whereSegment) {
// 去除括号
// while (fromItem instanceof ParenthesisFromItem) {
// fromItem = ((ParenthesisFromItem) fromItem).getFromItem();
// }
if (fromItem instanceof ParenthesedSelect) {
Select subSelect = (Select) fromItem;
processSelectBody(subSelect, whereSegment);
} else if (fromItem instanceof ParenthesedFromItem) {
logger.debug("Perform a subQuery, if you do not give us feedback");
}
}3.6 processFunction
处理函数,对参数中的子查询进行处理
/**
* 处理函数
* <p>支持: 1. select fun(args..) 2. select fun1(fun2(args..),args..)<p>
* <p> fixed gitee pulls/141</p>
*
* @param function
*/
protected void processFunction(Function function, final String whereSegment) {
ExpressionList<?> parameters = function.getParameters();
if (parameters != null) {
parameters.forEach(expression -> {
if (expression instanceof Select) {
processSelectBody(((Select) expression), whereSegment);
} else if (expression instanceof Function) {
processFunction((Function) expression, whereSegment);
} else if (expression instanceof EqualsTo) {
if (((EqualsTo) expression).getLeftExpression() instanceof Select) {
processSelectBody(((Select) ((EqualsTo) expression).getLeftExpression()), whereSegment);
}
if (((EqualsTo) expression).getRightExpression() instanceof Select) {
processSelectBody(((Select) ((EqualsTo) expression).getRightExpression()), whereSegment);
}
}
});
}
}3.7 processJoins
该方法用于解析和重写JOIN连接部分的SQL,将被驱动表(要保留部分数据)的过滤条件追加在ON条件上,并确定最终的驱动表(要保留全部数据)到底是哪一张,该方法实现的功能虽然简单,但逻辑却是该类所有的方法中最复杂的。
/**
* 处理 joins
*
* @param mainTables 哪些表是过滤条件要放在最后的where后面的主表,暂时是from后面的表,但是会根据JOIN类型的不同对主子表进行修改
* @param joins 连接的表及其连接条件
*/
private List<Table> processJoins(List<Table> mainTables, List<Join> joins, final String whereSegment) {
// join 表达式中最终的主表
Table mainTable = null;
// 当前 join 的左表
Table leftTable = null;
if (mainTables.size() == 1) {
mainTable = mainTables.get(0);
leftTable = mainTable;
}
//对于 on 表达式写在最后的 join,需要记录下前面多个 on 的表名
Deque<List<Table>> onTableDeque = new LinkedList<>();
for (Join join : joins) {
// 处理 on 表达式
FromItem joinItem = join.getRightItem();
List<Table> joinTables = null;
// //join的对象是表,将表存入joinTables
if (joinItem instanceof Table) {
joinTables = new ArrayList<>();
joinTables.add((Table) joinItem);
}
// 可被查询的一个带着括号的语法结构,但是又不是子查询(select ...),一般不会走到这个分支
else if (joinItem instanceof ParenthesedFromItem) {
joinTables = processSubJoin((ParenthesedFromItem) joinItem, whereSegment);
}
if (joinTables != null) {
// 如果是隐式内连接,from和join的表在语法上没有谁是驱动谁是被驱动
if (join.isSimple()) {
mainTables.addAll(joinTables);
continue;
}
Table joinTable = joinTables.get(0);
List<Table> onTables = null;
// 右连接
if (join.isRight()) {
// 因为取右表所有,驱动表和被驱动表交换
mainTable = joinTable;
mainTables.clear();
if (leftTable != null) {
// leftTable原本是驱动表,right join的新表后,要作为被驱动表
onTables = Collections.singletonList(leftTable);
}
}
// 内连接本就是取得两表交集,无论哪个表的条件都加在ON上,过滤条件即为查询条件,不区分谁是驱动谁是被驱动
else if (join.isInner()) {
if (mainTable == null) {
onTables = Collections.singletonList(joinTable);
} else {
onTables = Arrays.asList(mainTable, joinTable);
}
mainTable = null;
mainTables.clear();
}
// left join的情况,表的地位不需调整,from后的表是驱动表,on的表是被驱动表
else {
onTables = Collections.singletonList(joinTable);
}
// 将新的驱动表回写mainTables,用于拼接过滤条件在where后
if (mainTable != null && !mainTables.contains(mainTable)) {
mainTables.add(mainTable);
}
// 获取 join 尾缀的 on 表达式列表
Collection<Expression> originOnExpressions = join.getOnExpressions();
// 正常 join on 表达式只有一个,立刻处理
if (originOnExpressions.size() == 1 && onTables != null) {
List<Expression> onExpressions = new LinkedList<>();
onExpressions.add(builderExpression(originOnExpressions.iterator().next(), onTables, whereSegment));
join.setOnExpressions(onExpressions);
/*
记录下本次JOIN后驱动表是哪个
RIGHT JOIN:join后的表是驱动表
INNER JOIN:join后的表作为驱动表
LEFT JOIN: from后面的是驱动表
*/
leftTable = mainTable == null ? joinTable : mainTable;
continue;
}
// 表名压栈,忽略的表压入 null,以便后续不处理
onTableDeque.push(onTables);
// 尾缀多个 on 表达式的时候统一处理
if (originOnExpressions.size() > 1) {
Collection<Expression> onExpressions = new LinkedList<>();
for (Expression originOnExpression : originOnExpressions) {
List<Table> currentTableList = onTableDeque.poll();
if (CollectionUtils.isEmpty(currentTableList)) {
onExpressions.add(originOnExpression);
} else {
onExpressions.add(builderExpression(originOnExpression, currentTableList, whereSegment));
}
}
join.setOnExpressions(onExpressions);
}
leftTable = joinTable;
}
// join的不是表,可能是一个子查询,如是,对子查询中的SQL进行解析和追加条件
else {
processOtherFromItem(joinItem, whereSegment);
leftTable = null;
}
}
return mainTables;
}解读:
这里假设每张表都追加一个scope = 12的过滤条件用于数据权限或多租户等功能,这里用几种类型的SQL测试用例来解读该方法,其中有些形式的SQL写法在开发中基本不会用到,但是还是列举出来一一分析下
3.7.1 隐式INNER JOIN
SELECT u.id, u.name FROM userinfo u, dept d, role r
WHERE u.p = 1
AND u.dept_id = d.id
AND u.rid = r.id jsqlparser解析这种隐式内连接SQL时,会默认将from后面接的第一个表userinfo作为驱动表,传入List<Table> mainTables,剩下的表默认作为非驱动表在List<Join> joins中,在隐式内连接中,因为需要取多表交集,语法上实际是没有谁驱动谁的概念的,只要当前的JOIN满足if (join.isSimple()) == true,则当前JOIN的表也添加到mainTables中,并continue结束当前JOIN条件的解析,实际上隐式内连接的情况下List<Join> joins中的JOIN都满足if (join.isSimple()) == true,最后所有JOIN的表都会被加入mainTables中,最终在where上追加过滤条件,得到SQL如下:
SELECT u.id, u.name FROM userinfo u, dept d, role r
WHERE u.p = 1
AND u.dept_id = d.id
AND u.rid = r.id
AND userinfo.scope = 12
AND dept.scope = 12
AND role.scope = 123.7.2 INNER JOIN
SELECT u.id, u.name
FROM userinfo u
INNER JOIN dept d ON u.dept_id = d.id
INNER JOIN role r ON u.rid = r.id
WHERE u.p = 1INNER JOIN的情况和隐式内连接的情况类似,都是取多张表的交集,传入List<Table> mainTables中的唯一的元素是userinfo,List<Join> joins中依次是INNER JOIN的两张表dept,role,解析第一个inner join时,userinfo,dept两表都会保存到onTables中,这会将两表各自的scope = 12过滤条件依次追加在当前inner join dept的ON后,解析到第二个inner join的表时,则是把解析到的role表加入到onTables中,同理会将这个表的过滤条件scope = 12追加在当前inner join role的ON后,第三个和更后面的JOIN的规则和第二个是一样的。
因此,和隐式内连接不同的是,INNER JOIN下过滤条件不会加在where上,而是将过滤条件全部加在每个JOIN的ON后面,最终得到SQL:
SELECT u.id, u.name
FROM userinfo u
INNER JOIN dept d ON u.dept_id = d.id AND userinfo.scope = 12 AND dept.scope = 12
INNER JOIN role r ON u.rid = r.id AND role.scope = 12
WHERE u.p = 13.7.3 LEFT JOIN
SELECT u.id, u.name
FROM userinfo u
LEFT JOIN dept d ON u.dept_id = d.id
LEFT JOIN role r ON u.rid = r.id
WHERE u.p = 1 LEFT JOIN取的是FROM表的全部数据,是最简单的一种情况,方法开始执行时,参数mainTables中传入userinfo,joins中存放的则是dept,role两张表,局部变量mainTable和leftTable均为userinfo,因为LEFT JOIN取的是userinfo表的全部数据,因此mainTables中的userinfo就是驱动表,过滤条件加在WHERE上。LEFT JOIN的dept和role两张表都是被驱动表,过滤条件加在ON上。
SELECT u.id, u.name
FROM userinfo u
LEFT JOIN dept d ON u.dept_id = d.id AND dept.scope = 12
LEFT JOIN role r ON u.rid = r.id AND role.scope = 12
WHERE u.p = 1 AND userinfo.scope = 123.7.4 RIGHT JOIN
SELECT u.id, u.name
FROM userinfo u
RIGHT JOIN dept d ON u.dept_id = d.id
RIGHT JOIN role r ON u.rid = r.id
WHERE u.p = 1 RIGHT JOIN取的是JOIN后的表的全部数据,和LEFT JOIN正好相反,方法开始执行时,参数mainTables中传入userinfo,joins中存放的则是dept,role两张表,局部变量mainTable和leftTable均为userinfo
循环第一个JOIN,首先交换驱动和非驱动表,mainTable = joinTable将dept赋给mainTable,原先的userinfo放到onTables中并追加过滤条件到ON上,再将dept放进mainTables,交换完成后,本次JOIN的驱动表dept再赋给leftTable记录下来用于下次JOIN解析
第二个JOIN,仍然是右连接,role将作为驱动表取代上次的dept,因此mainTable = joinTable将role赋给mainTable,leftTable依然记录着上次JOIN的驱动表dept,但本次RIGHT JOIN中dept已经变为被驱动表,所以dept放到onTables中追加过滤条件到本次JOIN的ON上,从而缩小上次结果集的范围
更多JOIN以此类推,RIGHT JOIN中,越是最后JOIN的表越“大“,循环结束后,role作为最终的驱动表,在where上追加过滤条件,最终得到SQL:
SELECT u.id, u.name
FROM userinfo u
RIGHT JOIN dept d ON u.dept_id = d.id AND userinfo.scope = 12
RIGHT JOIN role r ON u.rid = r.id AND dept.scope = 12
WHERE u.p = 1 AND role.scope = 123.7.5 先INNER再RIGHT
SELECT u.id, u.name
FROM userinfo u
INNER JOIN dept d ON u.dept_id = d.id
RIGHT JOIN role r ON u.rid = r.id
WHERE u.p = 1 这种情况下解析第一个INNER JOIN的逻辑和之前的是一样的,userinfo和dept同时作为驱动表,把过滤条件加在ON上,然后默认驱动表是当前JOIN的dept,并赋值给leftTable,当解析第二个的RIGHT JOIN的role表时,role表成为最终查出全部数据的驱动表,因此为上次赋值给leftTable的dept表追加过滤条件到本次RIGHT JOIN role的ON后,缩小上次JOIN的结果集范围,并最终将role保存到mainTables在where上追加过滤条件,实现查出role的独有加role和上次inner join结果集的共有,得到如下SQL:
SELECT u.id, u.name
FROM userinfo u
INNER JOIN dept d ON u.dept_id = d.id AND userinfo.scope = 12 AND dept.scope = 12
RIGHT JOIN role r ON u.rid = r.id AND dept.scope = 12
WHERE u.p = 1 AND role.scope = 123.7.6 先RIGHT再INNER
SELECT u.id, u.name
FROM userinfo u
RIGHT JOIN dept d ON u.dept_id = d.id
INNER JOIN role r ON u.rid = r.id
WHERE u.p = 1 第一个RIGHT JOIN和之前的一样,首先交换表,mainTable = joinTable将dept赋给mainTable,原先的userinfo放到onTables中并追加过滤条件到ON上,再将dept放进mainTables,交换完成后,本次JOIN的驱动表dept再赋给leftTable记录下来用于下次JOIN解析,第二次循环的INNER JOIN是要把当前role表和上次的RIGHT JOIN的结果集取交集,因此会将上次的驱动表dept和当前INNER JOIN的表role都加在本次JOIN的ON上做过滤条件拼接就够了,不需要在where拼接任何条件,因此会清空mainTables,得到SQL如下:
SELECT u.id, u.name
FROM userinfo u
RIGHT JOIN dept d ON u.dept_id = d.id AND userinfo.scope = 12
INNER JOIN role r ON u.rid = r.id AND dept.scope = 12 AND role.scope = 12
WHERE u.p = 13.7.7 先INNER再LEFT
SELECT u.id, u.name
FROM userinfo u
INNER JOIN dept d ON u.dept_id = d.id
LEFT JOIN role r ON u.rid = r.id
WHERE u.p = 1 这种情况第一次循环先处理INNER JOIN,将userinfo和dept两表的过滤条件加在第一个INNER JOIN的ON上,mainTables没有元素,第二次循环处理LEFT JOIN时,因为要取上次INNER JOIN结果的所有加上次INNER JOIN结果和role表的共有,因此将过滤条件加在LEFT JOIN role的ON上缩小role表的范围即可,得到SQL:
SELECT u.id, u.name
FROM userinfo u
INNER JOIN dept d ON u.dept_id = d.id AND userinfo.scope = 12 AND dept.scope = 12
LEFT JOIN role r ON u.rid = r.id AND role.scope = 12
WHERE u.p = 13.7.8 先LEFT再INNER
SELECT u.id, u.name
FROM userinfo u
LEFT JOIN dept d ON u.dept_id = d.id
INNER JOIN role r ON u.rid = r.id
WHERE u.p = 1 解析LEFT JOIN时,取from表的全部,因此驱动表就是userinfo,INNER JOIN时又需要取role和上次LEFT JOIN结果集的交集,因此会将驱动表userinfo和role表的过滤条件加在INNER JOIN的ON上面,得到SQL如下:
SELECT u.id, u.name
FROM userinfo u
LEFT JOIN dept d ON u.dept_id = d.id AND dept.scope = 12
INNER JOIN role r ON u.rid = r.id AND userinfo.scope = 12 AND role.scope = 12
WHERE u.p = 13.7.9 先RIGHT再LEFT
SELECT u.id, u.name
FROM userinfo u
RIGHT JOIN dept d ON u.dept_id = d.id
LEFT JOIN role r ON u.rid = r.id
WHERE u.p = 1 解析第一个RIGHT JOIN时,JOIN的表要查出全部数据,是驱动表,因此通过mainTable = joinTable;将dept设置为驱动表,并将dept存入mainTables,userinfo表存入onTables中作为被驱动表,将userinfo的过滤条件追加在ON上。
解析第二个LEFT JOIN时,要取上次JOIN的结果集的全部,role表作为当前的joinTable存入onTables,将过滤条件追加在当前JOIN的ON上,mainTables存的是主导上次结果集的表dept,在本次JOIN结束后,dept表的过滤条件加在最终的WHERE上,得到SQL:
SELECT u.id, u.name
FROM userinfo u
RIGHT JOIN dept d ON u.dept_id = d.id AND userinfo.scope = 12
LEFT JOIN role r ON u.rid = r.id AND role.scope = 12
WHERE u.p = 1 AND dept.scope = 123.7.10 先LEFT再RIGHT
SELECT u.id, u.name
FROM userinfo u
LEFT JOIN dept d ON u.dept_id = d.id
RIGHT JOIN role r ON u.rid = r.id
WHERE u.p = 1解析第一个LEFT JOIN时,结果集需要取userinfo表的全部,mainTable, leftTable的值都是userinfo,mainTables中唯一的元素也是userinfo,LEFT JOIN dept直接把JOIN的dept表的过滤条件追加在ON上。
解析第二个RIGHT JOIN role时,最终的结果集要以role表为准了,于是mainTable赋值为role表,将mainTables清空,leftTable不为空的话,存入onTables中,于是userinfo表将在本次JOIN的ON上追加过滤条件,role表将存入到mainTables中在WHERE上追加过滤条件,得到SQL如下:
SELECT u.id, u.name
FROM userinfo u
LEFT JOIN dept d ON u.dept_id = d.id AND dept.scope = 12
RIGHT JOIN role r ON u.rid = r.id AND userinfo.scope = 12
WHERE u.p = 1 AND role.scope = 123.7.11 FROM子查询JOIN表
LEFT JOIN:
SELECT u.id, u.name
FROM (SELECT * FROM userinfo ) u
LEFT JOIN dept d ON u.dept_id = d.id
LEFT JOIN role r ON u.rid = r.id
WHERE u.p = 1这种情况下,from后的是子查询,参数mainTables元素数为0,dept表加入到onTables中在ON上追加过滤条件,但是from后的子查询的过滤条件追加已经在子查询解析重写中完成,因此if (mainTable != null && !mainTables.contains(mainTable))不满足,mainTables中没有要追加条件到where上的表,如第二次还是LEFT JOIN同理,最终得到SQL如下:
SELECT u.id, u.name
FROM (SELECT * FROM userinfo WHERE userinfo.scope = 12) u
LEFT JOIN dept d ON u.dept_id = d.id AND dept.scope = 12
LEFT JOIN role r ON u.rid = r.id AND role.scope = 12
WHERE u.p = 1RIGHT JOIN:
SELECT u.id, u.name
FROM (SELECT * FROM userinfo ) u
RIGHT JOIN dept d ON u.dept_id = d.id
RIGHT JOIN role r ON u.rid = r.id
WHERE u.p = 1 这种情况,from后的是子查询,参数mainTables元素数为0,leftTable一开始肯定也为null,因此第一个RIGHT JOIN后面没有ON过滤条件,但是第一个JOIN的dept表会被mainTable = joinTable设置为驱动表,onTables没有元素会最终走到leftTable = joinTable将dept设置为leftTable,第二次RIGHT JOIN时就会追加dept的过滤条件在当前的ON上来缩小上次JOIN的结果集,得到SQL如下:
SELECT u.id, u.name
FROM (SELECT * FROM userinfo WHERE userinfo.scope = 12) u
RIGHT JOIN dept d ON u.dept_id = d.id
RIGHT JOIN role r ON u.rid = r.id AND dept.scope = 12
WHERE u.p = 1 AND role.scope = 123.7.12 FROM表JOIN子查询
RIGHT JOIN:
SELECT u.id, u.name
FROM userinfo u
RIGHT JOIN (SELECT * FROM dept ) d ON u.dept_id = d.id
RIGHT JOIN (SELECT * FROM role ) r ON u.rid = r.id
WHERE u.p = 1 这样的SQL处理起来比较简单,因为JOIN的都是子查询而不是表,因此会执行processOtherFromItem(joinItem, whereSegment)将子查询表追加的条件直接加在子查询语句的where上面,主SQL语句的条件不需要区分驱动表和非驱动表和各个表的过滤条件在ON或WHERE的位置,处理完子查询后,参数List<Table> mainTables会原样返回,FROM后面的表直接在WHERE上拼接过滤条件,最终得到SQL:
SELECT u.id, u.name
FROM userinfo u
RIGHT JOIN (SELECT * FROM dept WHERE dept.scope = 12) d ON u.dept_id = d.id
RIGHT JOIN (SELECT * FROM role WHERE role.scope = 12) r ON u.rid = r.id
WHERE u.p = 1 AND userinfo.scope = 12LEFT JOIN:
SELECT u.id, u.name
FROM userinfo u
LEFT JOIN (SELECT * FROM dept ) d ON u.dept_id = d.id
LEFT JOIN (SELECT * FROM role ) r ON u.rid = r.id
WHERE u.p = 1 处理LEFT的情况和RIGHT是一样的,得到的SQL形式也相同:
SELECT u.id, u.name
FROM userinfo u
LEFT JOIN (SELECT * FROM dept WHERE dept.scope = 12) d ON u.dept_id = d.id
LEFT JOIN (SELECT * FROM role WHERE role.scope = 12) r ON u.rid = r.id
WHERE u.p = 1 AND userinfo.scope = 123.7.13 FROM子查询JOIN子查询
SELECT u.id, u.name
FROM (SELECT * FROM userinfo ) u
RIGHT JOIN (SELECT * FROM dept ) d ON u.dept_id = d.id
RIGHT JOIN (SELECT * FROM role ) r ON u.rid = r.id
WHERE u.p = 1这种情况本质上和FROM表JOIN子查询是一样的
SELECT u.id, u.name
FROM (SELECT * FROM userinfo WHERE userinfo.scope = 12) u
RIGHT JOIN (SELECT * FROM dept WHERE dept.scope = 12) d ON u.dept_id = d.id
RIGHT JOIN (SELECT * FROM role WHERE role.scope = 12) r ON u.rid = r.id
WHERE u.p = 13.7.14 不支持的情况
processJoins()方法似乎并不是万能的,有几种我遇到的不能支持的极端情况:
1.JOIN表和JOIN子查询混用时,使用了RIGHT会导致丢掉某个表的过滤条件
以下两个是重写过的SQL,都会导致userinfo表的scope条件丢失
SELECT u.id, u.name
FROM userinfo u
LEFT JOIN (SELECT * FROM dept WHERE dept.scope = 12) d ON u.dept_id = d.id
RIGHT JOIN role r ON u.rid = r.id
LEFT JOIN (SELECT * FROM job WHERE job.scope = 12) j ON u.jid = j.id
WHERE u.p = 1 AND role.scope = 12SELECT u.id, u.name
FROM userinfo u
RIGHT JOIN (SELECT * FROM dept WHERE dept.scope = 12) d ON u.dept_id = d.id
RIGHT JOIN role r ON u.rid = r.id
WHERE u.p = 1 AND role.scope = 122.from子查询后,left和right混用时,会导致表的范围限制出现问题,因为找不到上次结果集范围的基准表是哪个了
例:这是一个重写过的SQL,因为from后的表不存在(因为是子查询),在执行leftTable = mainTable == null ? joinTable时,将left join的dept表错误的作为了驱动表,导致下次right join时以dept表为基准,将dept又追加一次dept.scope = 12,实际应当以(SELECT * FROM userinfo WHERE userinfo.scope = 12)为基准,这样就导致(SELECT * FROM userinfo WHERE userinfo.scope = 12)的记录不全
SELECT u.id, u.name
FROM (SELECT * FROM userinfo WHERE userinfo.scope = 12) u
LEFT JOIN dept d ON u.dept_id = d.id AND dept.scope = 12
RIGHT JOIN role r ON u.rid = r.id AND dept.scope = 12
WHERE u.p = 1 AND role.scope = 123.case表达式中如出现select,默认不处理,可能是因为这里的select条件不影响整体查询结果的范围,没有处理的必要
例:
SELECT
CASE
WHEN id >= 90 THEN (SELECT id FROM system_users WHERE parent_dept_id = 9)
WHEN id >= 80 THEN (SELECT id FROM system_users WHERE parent_dept_id = 6)
WHEN (SELECT id FROM system_users WHERE parent_dept_id = 5) >= 70
THEN (SELECT id FROM system_users WHERE parent_dept_id = 5) ELSE 100
END AS grade
FROM system_users WHERE system_users.scope = 123.7.15 小结
processJoins()方法针JOIN的表进行解析重写,并对照FROM后面的表根据每次JOIN结果集的范围确定每张表在当前JOIN中的角色,从而调整要追加的条件的位置是在ON上还是WHERE上,做到既要精准的进行条件限制,又不能破坏原有SQL逻辑应当得到的结果集范围
3.8 processSubJoin
sub join的情况,目前还没遇到过,之后再补充,这个分支应该很少走
/**
* 处理 sub join
*
* @param subJoin subJoin
* @return Table subJoin 中的主表
*/
private List<Table> processSubJoin(ParenthesedFromItem subJoin, final String whereSegment) {
List<Table> mainTables = new ArrayList<>();
while (subJoin.getJoins() == null && subJoin.getFromItem() instanceof ParenthesedFromItem) {
subJoin = (ParenthesedFromItem) subJoin.getFromItem();
}
if (subJoin.getJoins() != null) {
List<Table> list = processFromItem(subJoin.getFromItem(), whereSegment);
mainTables.addAll(list);
processJoins(mainTables, subJoin.getJoins(), whereSegment);
}
return mainTables;
}3.9 processFromItem
对FROM后面的结构进行解析,解析出的有表(Table)或子查询(ParenthesedSelect)以及(table1 join table2)等结构,分别处理
private List<Table> processFromItem(FromItem fromItem, final String whereSegment) {
// 处理括号括起来的表达式
// while (fromItem instanceof ParenthesedFromItem) {
// fromItem = ((ParenthesedFromItem) fromItem).getFromItem();
// }
List<Table> mainTables = new ArrayList<>();
// 无 join 时的处理逻辑
if (fromItem instanceof Table) {
Table fromTable = (Table) fromItem;
mainTables.add(fromTable);
} else if (fromItem instanceof ParenthesedFromItem) {
// SubJoin 类型则还需要添加上 where 条件
List<Table> tables = processSubJoin((ParenthesedFromItem) fromItem, whereSegment);
mainTables.addAll(tables);
} else {
// 处理下 fromItem
processOtherFromItem(fromItem, whereSegment);
}
return mainTables;
}3.10 builderExpression
刚方法用于对解析出来的表在已有的条件上追加过滤条件,在FROM后面和ON后面解析出来的表和对应条件都会传到在这个方法,先将传进来的表追加条件并拼接成AND结构,再判断已有条件是使用AND还是OR连接,如果已有的条件是OR连接,则将已有条件用小括号括起来再去AND要追加的条件,如果已有条件就是AND连接的,则把要追加的条件和已有条件直接AND相连即可
/**
* 处理条件
*/
protected Expression builderExpression(Expression currentExpression, List<Table> tables, final String whereSegment) {
// 没有表需要处理直接返回
if (CollectionUtils.isEmpty(tables)) {
return currentExpression;
}
// 构造每张表的条件
List<Expression> expressions = tables.stream()
.map(item -> buildTableExpression(item, currentExpression, whereSegment))
.filter(Objects::nonNull)
.collect(Collectors.toList());
// 没有表需要处理直接返回
if (CollectionUtils.isEmpty(expressions)) {
return currentExpression;
}
// 注入的表达式
Expression injectExpression = expressions.get(0);
// 如果有多表,则用 and 连接
if (expressions.size() > 1) {
for (int i = 1; i < expressions.size(); i++) {
injectExpression = new AndExpression(injectExpression, expressions.get(i));
}
}
if (currentExpression == null) {
return injectExpression;
}
if (currentExpression instanceof OrExpression) {
// 已有条件是个OR结构,要先用括号括起来
return new AndExpression(new Parenthesis(currentExpression), injectExpression);
} else {
// 已有条件是个AND结构,直接拼接在一起
return new AndExpression(currentExpression, injectExpression);
}
}3.11 buildTableExpression
该方法本是BaseMultiTableInnerInterceptor中的一个抽象方法,用于确定对某个表要拼接的过滤条件具体是什么,由子类实现重写,这里先拼接一个scope = 12的过滤条件用于测试
/**
* 构建数据库表的查询条件
*
* @param table 表对象
* @param where 当前where条件
* @param whereSegment 所属Mapper对象全路径
* @return 需要拼接的新条件(不会覆盖原有的where条件,只会在原有条件上再加条件),为 null 则不加入新的条件
*/
public Expression buildTableExpression(final Table table, final Expression where, final String whereSegment) {
System.out.println(table);
return new EqualsTo(new Column(table.getName() + StringPool.DOT + "scope"), new LongValue(12));
}3.12 andExpression
这个方法用于给单个表在已有的条件上追加过滤条件,实现过程类似builderExpression,一般只有删除和更新SQL才会用到这个,因为一次只能删除或更新一张表。
protected Expression andExpression(Table table, Expression where, final String whereSegment) {
//获得where条件表达式
final Expression expression = buildTableExpression(table, where, whereSegment);
if (expression == null) {
return where;
}
if (where != null) {
if (where instanceof OrExpression) {
return new AndExpression(new Parenthesis(where), expression);
} else {
return new AndExpression(where, expression);
}
}
return expression;
}四、结束语
该类主要为其他业务类提供涉及多表复杂查询SQL的解析能力,本类代码实现有很多值得学习和借鉴之处,而且基本严谨的考虑到了所有的情况,解析SQL时,对查询的解析较为复杂,分很多步骤,因为查询语句可以写的很复杂来满足业务的需要,但是对删除和修改的解析就很简单了,因为MyBatis-Plus的插件在追加条件时基本没有对修改后或修改条件的值是子查询或删除条件的值是子查询的情况进行处理,仅仅处理针对update/delete本身的where条件,这一点后面的系列文章也许还会做进一步分析。
繁忙的工作中抽时间阅读并DEBUG贯通该类源码,并大致理解源码的含义再到形成本文大概花了20天左右,感觉对自己的提升还是很大的,学习到了一系列解析SQL语句的实现方案,使用这个类提供的功能时也能心中有数,做到开发时尽可能避免写出该类不支持解析的SQL结构,在遇到一些问题时,也能大致猜到问题出现在哪了。
"如果文章对您有帮助,可以请作者喝杯咖啡吗?"

微信支付

支付宝